ブラックボックス診断
本ページでは Takumi のブラックボックス診断の内部アーキテクチャを説明します。利用方法についてはブラックボックス診断(都度)をご参照ください。
概要
Takumi のブラックボックス診断は、LLM を活用したエージェントが人間のセキュリティエンジニアのように対象の Web アプリケーションに対して実際に攻撃を行い、脆弱性を発見します。エージェントはサンドボックス環境内のブラウザやシェルを操作してアプリケーションと通信し、発見した脆弱性は LLM に依存しない決定的な検証器(Oracle)によって検証されます。
診断の全体像は以下の通りです。
- エージェント が人間のセキュリティエンジニアのように振る舞い、サンドボックス��環境内の ブラウザ や シェル を操作して対象 Web アプリケーションに対して攻撃を実行する
- ブラウザ・シェルからの全通信は プロキシ を経由して記録される。通信ログは攻撃結果の分析や Oracle による検証に利用される
- SSRF 等の Out-of-Band(OOB)脆弱性の検出には、専用の コールバックサーバー が使用される
- 攻撃フェーズで発見された脆弱性は、可能な限り LLM に依存しない決定論的な Oracle によって検証されるため、再現不可能な脆弱性の仮説が排除される
環境分離
サンドボックス環境は 診断単位 で分離されます。各診断は専用の VM 内で実行され、ブラウザプロファイル、プロキシログ、ファイルシステムが他の診断と共有されることはありません。これにより、異なる診断対象間のデータ分離が保証されます。
診断の流れ
ブラックボックス診断では、エージェントが 偵察(Recon)、攻撃(Attack)、検証(Verify) の3つのフェーズを順に実行します。
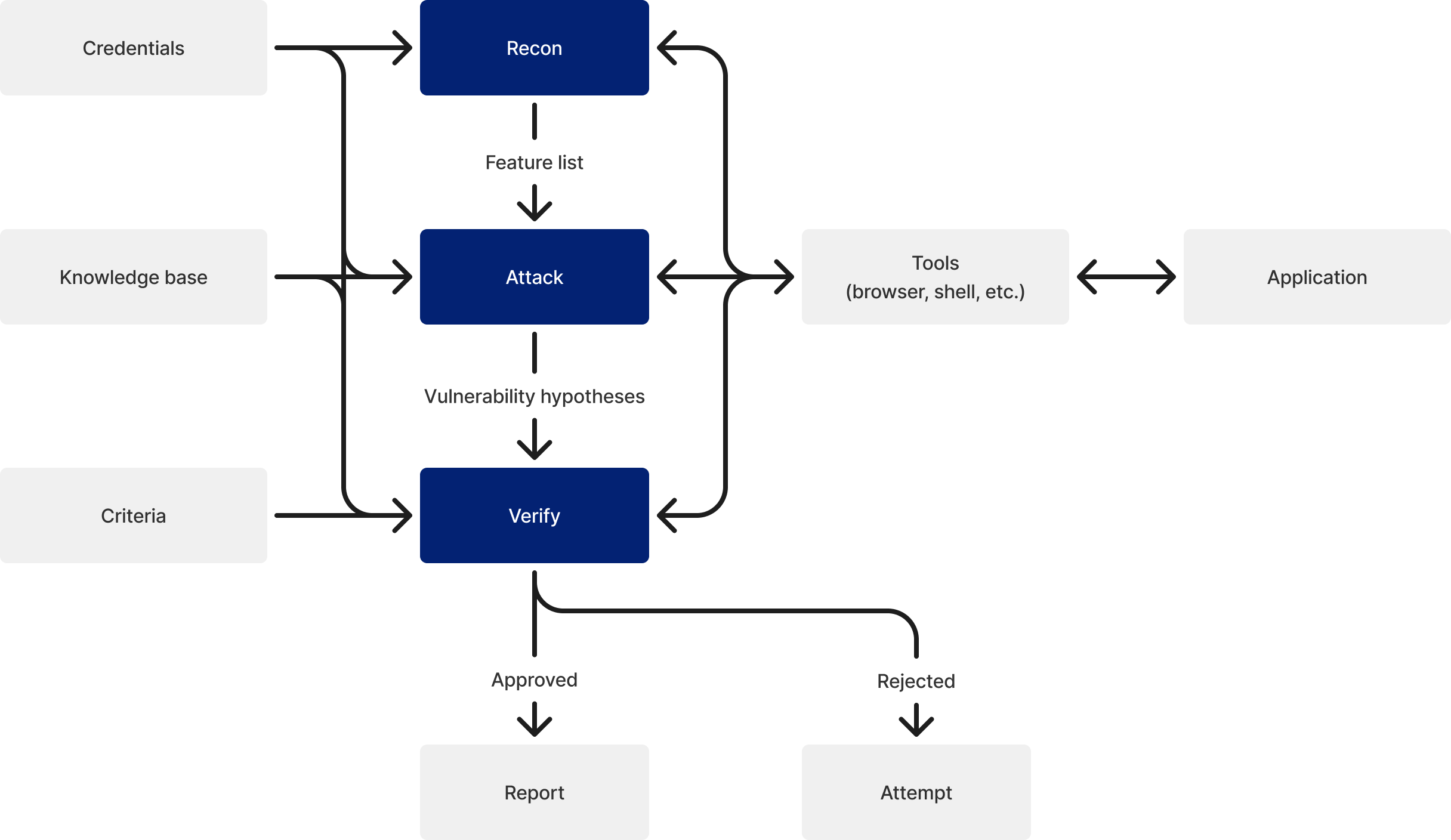
偵察フェ�ーズ
最初に、エージェントが対象アプリケーションをブラウザを用いて巡回し、機能(feature) を自動的に発見します。認証が必要な場合は、提供された認証情報を用いてサインインした上で巡回を行います。エージェントはアプリケーション内のリンクやフォームをたどりながら利用可能な機能を列挙し、各機能の特性(認証関連、決済関連、API エンドポイントなど)を分類します。さらに、各機能に紐づくエンドポイント(ページの URL や API パス)を特定し、後続の攻撃フェーズでテスト対象となるリクエスト先を記録します。
攻撃フェーズ
偵察フェーズで発見された各機能に対して、脆弱性の観点(インジェクション、XSS、認可不備など)を組み合わせ、エージェントが実際に攻撃を実行します。大半の観点はすべての機能に対して適用されますが、一部の観点は機能の特性に応じてフィルタリングされます。例えば、Clickjacking や CORS の観点はトップレベルの機能にのみ適用され、認証不備の観点は認証関連の機能にのみ適用されます。
エージェントはサンドボックス環境内で実行可能なツールを使い、対象アプリケーションに対して攻撃を行います。主なツールは以下の通りです。
- ブラウザ: ページ遷移、フォーム入力、クリック、JavaScript 実行、Cookie 検査など、実際のユーザーと同様の操作�を行う
- シェル: curl や Python スクリプトなどを用いて HTTP リクエストを直接送信する
- 通信ログ検索: HTTP プロキシが記録した全通信を検索し、攻撃の結果を分析する
- コールバックサーバー: SSRF など、アプリケーションから外部への通信を検出する
- ナレッジベース: 脆弱性の観点ごとの攻撃テクニック(ペイロード、バイパス手法など)を参照する
エージェントは攻撃の結果を分析し、脆弱性を発見した場合は Finding として記録します。記録された Finding は、別のエージェントによる改善提案と修正を経て最終的なレポートに反映されます。
脆弱性検証の仕組み
攻撃フェーズで発見された脆弱性は Oracle を用いて決定論的に検証されます。これは偽陽性(存在しない、あるいは、再現不可能な脆弱性)を排除するための仕組みです。
検証フロー
攻撃フェーズで記録された Finding は、以下の3段階を経て検証されます。
まず、アプリケーションの仕様が提供されている場合、Finding の内容がアプリケーションの意図された動作に該当しないかを確認します。例えば、「管理者は全ユーザーのデータを閲覧できる」と仕様に記載されている場合、そのような挙動が攻撃フェーズで確��認されたとしても、それはアクセス制御の不備ではなく正常な動作と判定されます。
次に、エージェントが Finding に記載された再現手順をもとに、実際に再現を試みます。攻撃フェーズで使用されたものと同じツール(ブラウザやシェルなど)を使い、脆弱性が本当に存在するかを再度確かめます。再現に失敗した場合、その Finding はここで棄却されます。
最後に、再現に成功した Finding に対して Oracle による検証を行います。Oracle は LLM ではなく、脆弱性の種別ごとに用意された専用のプログラムです。例えば XSS であれば「ブラウザコンソールに特定の値が出力されたか」、SQL インジェクションであれば「遅延をもたらすようなペイロードによって応答時間に差が生じたか」といった、客観的な基準で脆弱性の有無を判定します。
Oracle の種類
脆弱性の種別ごとに、専用の Oracle が用意されています。以下に、Oracle の例を示します。
| 脆弱性タイプ | 検証手法 |
|---|---|
| XSS | ブラウザコンソールに出力された Canary値(ユニークな数値)の検出 |
| SQL インジェクション | タイムベース検証(通常リクエストと遅延ペイロード付きリクエストの応答時間差を計測) |
| SSRF | コールバックサーバーへの OOB 通信の確認 |
| SSTI | プロキシログ内で計算式の評価結果(例: 2つの数の乗算結果)を検索 |
| パストラバーサル | プロキシログ内でファイル内容の既知パターンを検索 |
| アクセス制御(読み取り) | 認可済みユーザーと非認可ユーザーの2つのセッションで Canary 値を比較し、情報漏洩の有無を判定 |
| アクセス制御(書き込み) | 非認可ユーザーによる書き込み操作後、認可済みユーザーが変更の反映を確認 |
| オープンリダイレクト | ブラウザのリダイレクト先ドメインが攻撃者指定のドメインと一致するかを検証 |
| クリックジャッキング | X-Frame-Options および Content-Security-Policy の frame-ancestors ヘッダーの有無を検証 |
最終判定
最終的な判定は Oracle の結果のみで決まります。エージェントの判断は最終結果に影響しません。
Oracle が脆弱性を確認した場合、その Finding は脆弱性として報告されます。Oracle が脆弱性の存在を確認できなかった場合、攻撃フェーズで動作するエージェントが脆弱と判断していたとしても、その Finding は棄却されます。
この設計により、エージェントによって報告された偽陽性が構造的に排除されます。
非 LLM アーキテクチャとの比較
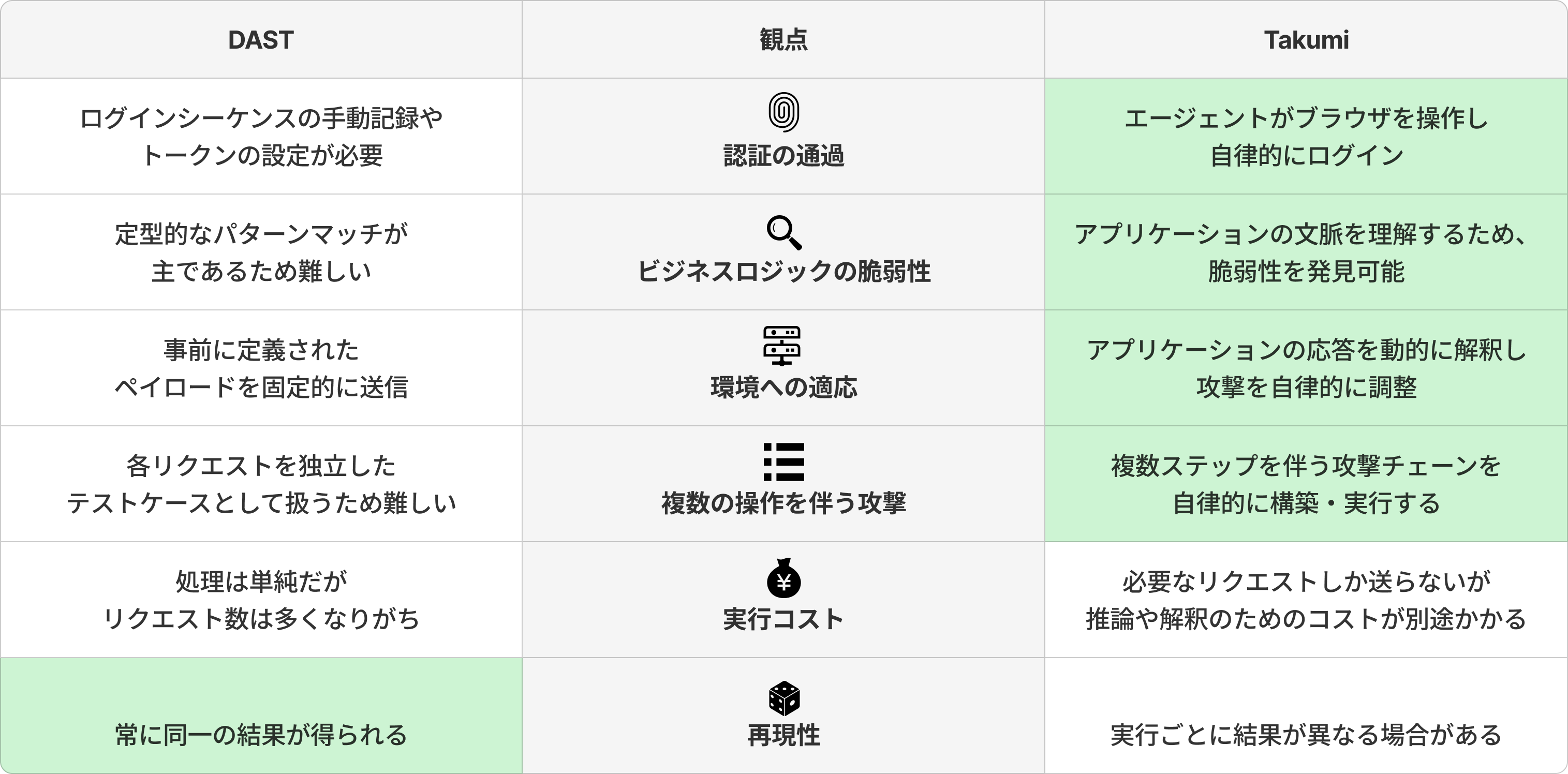
ここでは、Takumi のエージェントベースのアプローチと、従来型の動的アプリケーションセキュリティテスト(DAST)ツールを比較します。
従来型の DAST とは、Web アプリケーションに対して事前定義されたペイロードを送信し、その応答を解析することで脆弱性を検出するツールです。代表的なものに OWASP ZAP や Burp Suite のスキャン機能があります。
認証の通過
Web アプリケーションの多くの機能は認証後にのみアクセスできるため、ブラックボックス診断では認証フローを通過することが前提条件となります。
従来型の DAST で認証後の画面を診断するには、以下のような事前準備が必要です。
- ログインシーケンス(URL、パラメータ、リクエスト順序)を手動で記録する
- 有効なセッショントークンを手動で取得し、スキャナに設定する
- セッション失効時の再認証ロジックを設定する
この方式では、ログインフォームやログイン用の API の�仕様が変わるたびに設定の更新が必要です。また、ワンタイムパスワードやキャプチャを含む認証フロー、OAuth / SAML 等のリダイレクトを伴う認証フローでは、自動化自体が困難になります。
Takumi によるブラックボックス診断では、提供された認証情報を用いてエージェントがブラウザを操作し、ログイン処理を自律的に実行します。エージェントは画面上の UI を理解して操作するため、ログインシーケンスの事前記録は不要です。ログインに関する UI や API の構造が変わっても、エージェントがその場で適応します。
ビジネスロジックに関する脆弱性の発見
従来型の DAST は、往々にして「<script>alert(1)</script> を入力フィールドに送信し、レスポンスにそのまま反映されていれば XSS が存在する」といったように、定型的なペイロードの送信とレスポンスのパターンマッチで脆弱性を検出します。このアプローチは SQL インジェクションや XSS といった技術的な脆弱性には有効ですが、以下に示すような アプリケーションの文脈を理解しなければ検出できない脆弱性 には対応が困難です。
- IDOR(Insecure Direct Object Reference): ユーザープロフィール画面の URL が
/api/users/123の場合、ID を124に変えると他ユーザーのプロフィールが閲覧できてしまう。これを検出するには「123 は自分の ID であり、124 は他人の ID である。そして��、他人のプロフィールは閲覧できてはならない」という文脈の理解が必要であり、単にパラメータを変えて送信するだけでは判定できない - 権限昇格: 一般ユーザー権限のセッションで管理者向け API エンドポイント(例:
/api/admin/users)を呼び出すと、認可チェックの不備によりアクセスできてしまう。これを検出するには「このエンドポイントは管理者のみがアクセスできるべきである」というアプリケーションの権限モデルの理解が必要である - 制限のバイパス: EC サイトで、カート → 決済 → 注文確定 という順序が想定されているが、注文確定 API を直接呼び出すと、支払いが完了していない状態で商品の発送処理が開始されてしまう。これは個々のリクエストに問題があるのではなく、処理フローの前提条件のチェックに問題がある
Takumi によるブラックボックス診断では、エージェントがアプリケーションの機能や文脈を理解した上で攻撃を行うため、こうしたビジネスロジックに関する脆弱性を発見できます。例えば IDOR の検出では、エージェントがまず正規のユーザーとしてリソースにアクセスし、次に ID を別のユーザーのものに差し替えてアクセスを試み、レスポンスの内容を比較して不正なアクセスが成立するかを判定するといった柔軟な挙動を示します。
環境への適応
従来型の DAST は、往々にして事前に設定されたエンドポイントのリストに対して、同じく事前に定義されたペイロードを順番に送信します。このため、以下のような状況ではテストが無効になることがあります。
- 入力形式の不一致: アプリケーションの API の形式が変更された後、スキャナが古い形式のリクエストを送信してしまい、API 側でリクエストが拒否される
- 動的なトークン: CSRF トークンや Nonce など、リクエストごとに変化する値を正しく処理できず、サーバー側でリクエストが拒否される
Takumi によるブラックボックス診断では、エージェントがアプリケーションの応答を逐次解釈し、攻撃手法を動的に調整します。例えば、JAPI に対しては適切なリクエスト形式を事前にチェックしたり、CSRF トークンが必要な場合はページから値を取得してリクエストに含めたりするといった対応を自律的に行います。
複数の操作を伴う攻撃
従来型の DAST は、各リクエストを独立したテストケースとして扱います。つまり、「リクエスト A を送信し、そのレスポンスを元にリクエスト B を構築する」といった、複数のステップにまたがる攻撃シナリオを自律的に検証することは困難です。
しかし、実際のペネトレーションテストでは、以下のような複数ステップの攻撃が必要とされます。
- ユーザー A としてログインし、リソース X の ID を取得する → ユーザー B としてログインし直し、ユーザー A のリソース X にアクセスを試みる(IDOR の検証)
- 商品をカートに追加し、ク��ーポンを適用し、決済リクエストを送信する直前に価格パラメータを改ざんする(価格操作の検証)
- ファイルアップロード機能で SVG ファイルをアップロードし、そのファイルが表示されるページにアクセスして、埋め込まれた JavaScript が実行されるかを確認する(Stored XSS の検証)
Takumi によるブラックボックス診断では、エージェントがツールを駆使して、このような複数ステップにまたがる攻撃チェーンを自律的に構築・実行します。各ステップの結果を理解した上で次のステップを組み立てるため、人間のセキュリティエンジニアと同様の攻撃フローを再現できます。
実行コスト
従来型の DAST はペイロードリストの送信とレスポンスのパターンマッチが主な処理であり、1リクエストあたりの計算コストは低く抑えられます。一方で、大量の定型ペイロードを網羅的に送信するため、対象のエンドポイント数やペイロードの種類が多い場合にはリクエスト総数が膨大になります。
Takumi はエージェントがアプリケーションの応答を逐次解釈しながら攻撃を行うため、1リクエストあたりの計算コストは高くなります。一方で、エージェントが必要と判断した攻撃手法のみを選択的に試行するため、リクエスト総数は抑えられる傾向にあります。
このように、両者のコスト特性は異なり、どちらが低コストになるかは対象アプリケーションの規模や構成によって変わります。
再��現性
従来型の DAST は決定論的に動作します。同一のアプリケーションと設定に対して、何度実行しても常に同一の結果が得られます。
Takumi は LLM の確率的な性質上、同一アプリケーションに対する診断結果が実行ごとに若干異なることがあります。ある実行で発見された脆弱性が別の実行では発見されない、またはその逆が起こる可能性があります。